
Publications
 Under Review
Under Review Abs
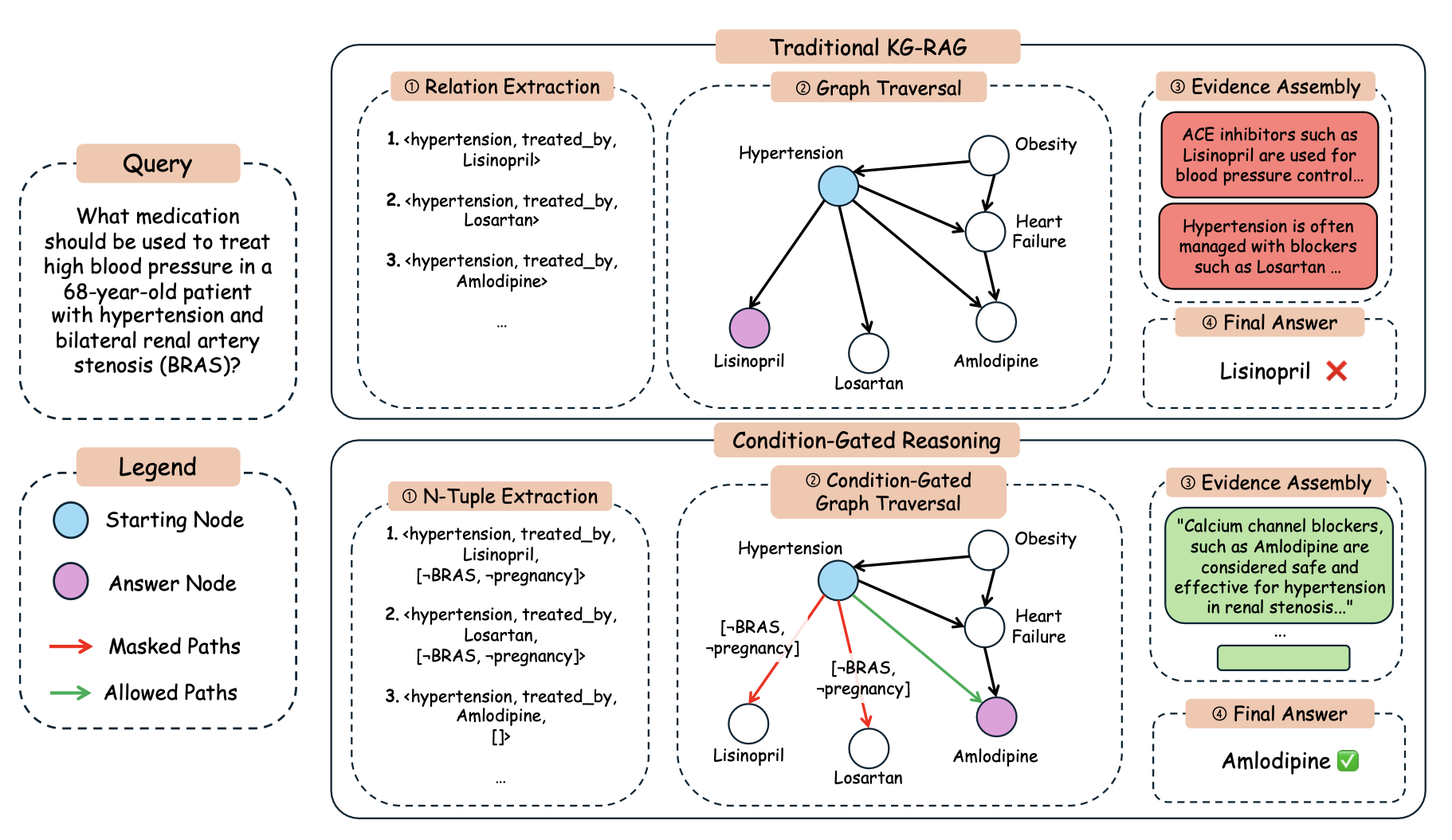
Current biomedical question answering (QA) systems often assume that medical knowledge applies uniformly, yet real-world clinical reasoning is inherently conditional: nearly every decision depends on patient-specific factors such as comorbidities and contraindications. Existing benchmarks do not evaluate such conditional reasoning, and retrieval-augmented or graph-based methods lack explicit mechanisms to ensure that retrieved knowledge is applicable to given context. To address this gap, we propose CondMedQA, the first benchmark for conditional biomedical QA, consisting of multi-hop questions whose answers vary with patient conditions. Furthermore, we propose Condition-Gated Reasoning (CGR), a novel framework that constructs condition-aware knowledge graphs and selectively activates or prunes reasoning paths based on query conditions. Our findings show that CGR more reliably selects condition-appropriate answers while matching or exceeding state-of-the-art performance on biomedical QA benchmarks, highlighting the importance of explicitly modeling conditionality for robust medical reasoning.
Bib
@article{parekh2026condition,
title={Condition-Gated Reasoning for Context-Dependent Biomedical Question Answering},
author={Parekh, Jash Rajesh and Kweon, Wonbin and Chan, Joey and Islamaj, Rezarta and Leaman, Robert and Jiang, Pengcheng and Wei, Chih-Hsuan and Wang, Zhizheng and Lu, Zhiyong and Han, Jiawei},
journal={arXiv preprint arXiv:2602.17911},
year={2026}
} Under Review
Under Review Abs
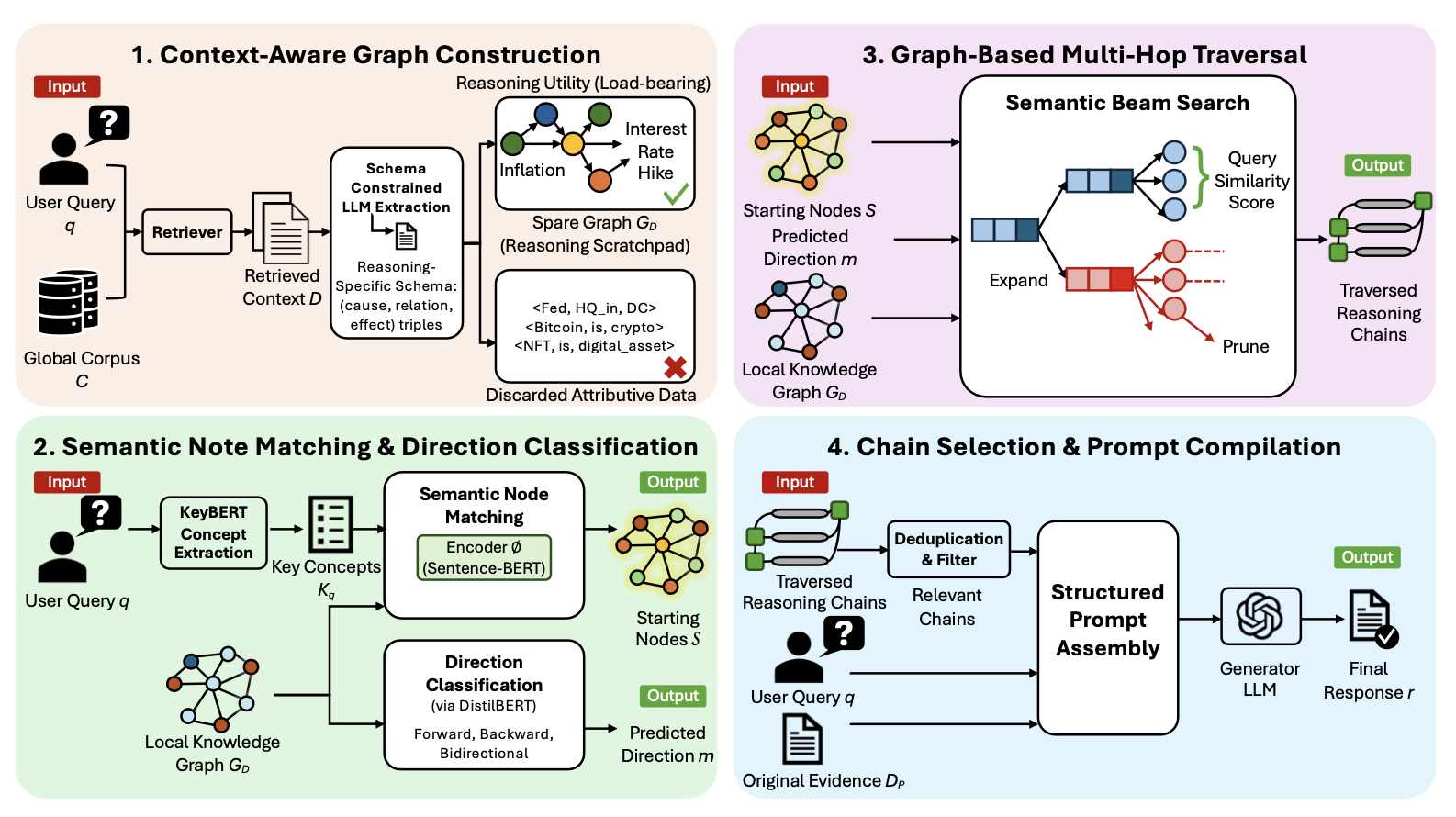
Recent advances in Large Language Models (LLMs) have significantly improved complex reasoning capabilities. Retrieval-Augmented Generation (RAG) has further extended these capabilities by grounding generation in dynamically retrieved evidence, enabling access to information beyond the model's training parameters. However, while RAG addresses knowledge availability, standard pipelines treat retrieved documents as independent, unstructured text chunks, forcing models to implicitly connect information across fragmented context. This limitation becomes critical for multi-hop queries, where answering correctly requires synthesizing information scattered across different documents. We present Structure-Augmented Reasoning Generation (SARG), a post-retrieval framework that addresses this gap by materializing explicit reasoning structures from retrieved context. SARG operates in three stages: extracting relational triples from retrieved documents via few-shot prompting, organizing these triples into a domain-adaptive knowledge graph, and performing multi-hop traversal to identify relevant reasoning chains. These chains, along with their associated text chunks, are then integrated into the generation prompt to explicitly guide the model's reasoning process. Importantly, SARG doesn't require custom retrievers or domain-specific fine-tuning. Instead, it functions as a modular layer compatible with all existing RAG pipelines. Extensive experiments on open-domain QA benchmarks and specialized reasoning datasets in finance and medicine demonstrate that SARG significantly outperforms state-of-the-art flat-context RAG baselines in both factual accuracy and reasoning coherence. Furthermore, by surfacing the exact traversal paths used during generation, SARG provides fully traceable and interpretable inference.
Bib
@article{parekh2025structure,
title={Structure-Augmented Reasoning Generation},
author={Parekh, Jash Rajesh and Jiang, Pengcheng and Han, Jiawei},
journal={arXiv preprint arXiv:2506.08364},
year={2025}
} Preprint
Preprint Abs
Workplace negotiations are undermined by psychological barriers, which can even derail well-prepared tactics. AI offers personalized and always-available negotiation coaching, yet its effectiveness for negotiation preparedness remains unclear. We built Trucey, a prototype AI coach grounded in Brett's negotiation model. We conducted a between-subjects experiment (N=267), comparing Trucey, ChatGPT, and a traditional negotiation Handbook, followed by in-depth interviews (N=15). While Trucey showed the strongest reductions in fear relative to both comparison conditions, the Handbook outperformed both AIs in usability and psychological empowerment. Interviews revealed that the Handbook's comprehensive, reviewable content was crucial for participants' confidence and preparedness. In contrast, although participants valued AI's rehearsal capability, its guidance often felt verbose and fragmented—delivered in bits and pieces that required additional effort—leaving them uncertain or overwhelmed. These findings challenge assumptions of AI superiority and motivate hybrid designs that integrate structured, theory-driven content with targeted rehearsal, clear boundaries, and adaptive scaffolds to address psychological barriers and support negotiation preparedness.
Bib
@article{duddu2025does,
title={Does AI Coaching Prepare us for Workplace Negotiations?},
author={Duddu, Veda and Parekh, Jash Rajesh and Mao, Andy and Min, Hanyi and Xiao, Ziang and Swain, Vedant Das and Saha, Koustuv},
journal={arXiv preprint arXiv:2509.22545},
year={2025}
} CHI '25
CHI '25 Abs
Client-Service Representatives (CSRs) are vital to organizations. Frequent interactions with disgruntled clients, however, disrupt their mental well-being. To help CSRs regulate their emotions while interacting with uncivil clients, we designed Care-Pilot, an LLM-powered assistant, and evaluated its efficacy, perception, and use. Our comparative analyses between 665 human and Care-Pilot-generated support messages highlight Care-Pilot's ability to adapt to and demonstrate empathy in various incivility incidents. Additionally, 143 CSRs assessed Care-Pilot's empathy as more sincere and actionable than human messages. Finally, we interviewed 20 CSRs who interacted with Care-Pilot in a simulation exercise. They reported that Care-Pilot helped them avoid negative thinking, recenter thoughts, and humanize clients; showing potential for bridging gaps in coworker support. Yet, they also noted deployment challenges and emphasized the indispensability of shared experiences. We discuss future designs and societal implications of AI-mediated emotional labor, underscoring empathy as a critical function for AI assistants for worker mental health.
Bib
@inproceedings{das2025ai,
title={AI on my Shoulder: Supporting Emotional Labor in Front-Office Roles with an LLM-Based Empathetic Coworker},
author={Das Swain, Vedant and Zhong, Qiuyue "Joy" and Parekh, Jash Rajesh and Jeon, Yechan and Zimmermann, Roy and Czerwinski, Mary P and Suh, Jina and Mishra, Varun and Saha, Koustuv and Hernandez, Javier},
booktitle={Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems},
pages={1--29},
year={2025}
} Remote Sensing '21
Remote Sensing '21 Abs
The large scale quantification of impervious surfaces provides valuable information for urban planning and socioeconomic development. Remote sensing and GIS techniques provide spatial and temporal information of land surfaces and are widely used for modeling impervious surfaces. Traditionally, these surfaces are predicted by computing statistical indices derived from different bands available in remotely sensed data, such as the Landsat and Sentinel series. More recently, researchers have explored classification and regression techniques to model impervious surfaces. However, these modeling efforts are limited due to lack of labeled data for training and evaluation. This in turn requires significant effort for manual labeling of data and visual interpretation of results. In this paper, we train deep learning neural networks using TensorFlow to predict impervious surfaces from Landsat 8 images. We used OpenStreetMap (OSM), a crowd-sourced map of the world with manually interpreted impervious surfaces such as roads and buildings, to programmatically generate large amounts of training and evaluation data, thus overcoming the need for manual labeling. We conducted extensive experimentation to compare the performance of different deep learning neural network architectures, optimization methods, and the set of features used to train the networks. The four model configurations labeled U-Net_SGD_Bands, U-Net_Adam_Bands, U-Net_Adam_Bands+SI, and VGG-19_Adam_Bands+SI resulted in a root mean squared error (RMSE) of 0.1582, 0.1358, 0.1375, and 0.1582 and an accuracy of 90.87%, 92.28%, 92.46%, and 90.11%, respectively, on the test set. The U-Net_Adam_Bands+SI Model, similar to the others mentioned above, is a deep learning neural network that combines Landsat 8 bands with statistical indices. This model performs the best among all four on statistical accuracy and produces qualitatively sharper and brighter predictions of impervious surfaces as compared to the other models.
Bib
@article{parekh2021automatic,
title={Automatic Detection of Impervious Surfaces from Remotely Sensed Data Using Deep Learning},
author={Parekh, Jash R and Poortinga, Ate and Bhandari, Biplov and Mayer, Timothy and Saah, David and Chishtie, Farrukh},
journal={Remote Sensing},
volume={13},
number={16},
pages={3166},
year={2021},
publisher={MDPI}
}Experience




